


еҪ“еүҚжҜ”иҫғеёёи§Ғзҡ„еӨ§ж•°жҚ®ж–№жЎҲеҹәжң¬жҳҜйҮҮз”ЁHadoopпјҢе…¶дёӯдҪҝз”ЁCDHжңҖдёәжҷ®йҒҚгҖӮдёҚиҝҮHadoopеӨ§ж•°жҚ®ж–№жЎҲеңЁеӨ§и§„жЁЎеңәжҷҜдјҡйҒҮеҲ°еҗ„з§ҚжҢ‘жҲҳпјҢд№ӢеүҚж–Үз« жңүеҒҡеҹәжң¬зҡ„еҲҶжһҗгҖҠHadoopеӨ§ж•°жҚ®еӯҳз®—еҲҶзҰ»йңҖиҰҒд»Җд№Ҳж ·зҡ„еӯҳеӮЁпјҹгҖӢгҖӮйҷӨжӯӨд№ӢеӨ–пјҢйқўеҜ№жө·йҮҸе°Ҹж–Ү件еӯҳеӮЁж—¶пјҢHadoopж–№жЎҲд№ҹеӯҳеңЁжҳҺжҳҫ瓶йўҲгҖӮ
01
NameNodeеҶ…еӯҳеҚ з”Ёй—®йўҳ
NameNodeжҳҜHDFSдёӯзҡ„з®ЎзҗҶиҖ…пјҢдё»иҰҒиҙҹиҙЈж–Ү件系з»ҹзҡ„е‘ҪеҗҚз©әй—ҙгҖҒйӣҶзҫӨй…ҚзҪ®дҝЎжҒҜе’Ңж•°жҚ®еқ—зҡ„еӨҚеҲ¶зӯүгҖӮNameNodeеңЁеҶ…еӯҳдёӯдҝқеӯҳж–Ү件系з»ҹдёӯжҜҸдёӘж–Ү件е’ҢжҜҸдёӘж•°жҚ®еқ—зҡ„еј•з”Ёе…ізі»пјҢд№ҹе°ұжҳҜе…ғж•°жҚ®гҖӮ
еңЁиҝҗиЎҢж—¶пјҢHDFSдёӯжҜҸдёӘж–Ү件гҖҒзӣ®еҪ•е’Ңж•°жҚ®еқ—зҡ„е…ғж•°жҚ®дҝЎжҒҜпјҲеӨ§зәҰ150еӯ—иҠӮпјүеҝ…йЎ»еӯҳеӮЁеңЁNameNodeзҡ„еҶ…еӯҳдёӯгҖӮж №жҚ®Clouderaзҡ„е»әи®®пјҢй»ҳи®Өжғ…еҶөдёӢпјҢдјҡдёәжҜҸдёҖзҷҫдёҮдёӘж•°жҚ®еқ—еҲҶй…ҚдёҖдёӘжңҖеӨ§зҡ„е Ҷз©әй—ҙ1GBпјҲдҪҶз»қдёҚе°ҸдәҺ1GB)гҖӮжүҖд»ҘжҲ‘们еҸҜд»Ҙи®Ўз®—еҫ—еҮәеҰӮжһңHDFSиҰҒеӯҳеӮЁ3дәҝдёӘж–Ү件пјҲжҜҸдёӘж–Ү件еҜ№еә”дёҖдёӘж•°жҚ®еқ—пјүпјҢеҲҷйңҖиҰҒиҮіе°‘300GBзҡ„еҶ…еӯҳз©әй—ҙгҖӮ
02
Hadoopдёӯзҡ„е°Ҹеқ—й—®йўҳ
иҝҷйҮҢзҡ„е°Ҹеқ—дёҖиҲ¬жҳҜжҢҮеқ—еӨ§е°ҸжҳҺжҳҫе°ҸдәҺHadoopзҡ„block sizeгҖӮдёҖиҲ¬жңүдёӨз§Қжғ…еҶөдјҡдә§з”ҹиҝҷдёӘй—®йўҳпјҡ
1гҖҒжө·йҮҸе°Ҹж–Ү件пјҢеҰӮ5дәҝзҡ„200kbе°Ҹж–Ү件пјӣ
2гҖҒжө·йҮҸе°Ҹеқ—пјҢеҰӮblock sizeжҳҜ128MBпјҢдҪҶеҠ иҪҪеҲ°HDFSзҡ„ж–Ү件йғҪжҳҜ130MBпјҢеҲҷдјҡеҮәзҺ°еӨ§йҮҸ2MBзҡ„blockгҖӮ
еӨ„зҗҶиҝҷз§ҚвҖңе°Ҹеқ—вҖқй—®йўҳеҸҜд»ҘйҖүжӢ©и°ғеӨ§block sizeжқҘи§ЈеҶіпјҢдҪҶи§ЈеҶіе°Ҹж–Ү件问йўҳеҚҙиҰҒеӨҚжқӮзҡ„еӨҡгҖӮ
03
е°Ҹж–Ү件зҡ„жқҘжәҗ
е°Ҹж–Ү件зҡ„жқҘжәҗжңүеҫҲеӨҡпјҢжҜ”иҫғе…ёеһӢзҡ„жңүд»ҘдёӢеҮ з§Қпјҡ
- жәҗж•°жҚ®дёәжө·йҮҸе°Ҹж–Ү件пјҢзӣҙжҺҘжӢ·иҙқеҲ°HDFSйӣҶзҫӨпјҢеҰӮдёҖдәӣеӣҫзүҮгҖҒзҹӯи§Ҷйў‘гҖҒзҹӯйҹійў‘зӯүж–Ү件пјӣ
- еңЁHadoopеӨ„зҗҶе®һж—¶жҲ–иҖ…еҮҶе®һж—¶и®Ўз®—еңәжҷҜдёӯпјҢеӨ§йғЁеҲҶж—¶еҖҷжҠҪеҸ–ж•°жҚ®зҡ„ж—¶й—ҙй—ҙйҡ”еҶіе®ҡдәҶж–Ү件зҡ„еӨ§е°ҸпјҢеҰӮжһңй—ҙйҡ”иҫғе°ҸпјҢжҜ”еҰӮжҜҸе°Ҹж—¶жҠҪеҸ–дёҖж¬ЎпјҢеҲҷз”ҹжҲҗзҡ„ж–Ү件еҸҜиғҪеҸӘжңүеҮ MBжҲ–еҚҒеҮ MBпјӣ
- з”ұ计算组件з”ҹжҲҗпјҢеҪ“MapReduceдёӯreduceж•°йҮҸи®ҫзҪ®иҝҮеӨҡпјҢе°ұеҸҜиғҪеҜјиҮҙд»»еҠЎиҝҗиЎҢз»“жһңеҸҳжҲҗNеӨҡе°Ҹж–Ү件гҖӮеҜ№дәҺHiveпјҢеҰӮжһңи®ҫзҪ®дәҶеҲҶеҢәиЎЁпјҢеҪ“иЎЁзҡ„ж•°жҚ®йҮҸдёҚеӨ§ж—¶пјҢеҲҶеҢәи¶ҠеӨҡпјҢеҲҷжҜҸдёӘеҲҶеҢәзҡ„ж•°жҚ®йҮҸи¶Ҡе°ҸпјҢеҜ№еә”зҡ„еҲҶеҢәиЎЁж–Ү件д№ҹе°ұдјҡи¶Ҡе°ҸгҖӮ
04
еҶ…еӯҳиҝҮеӨ§зҡ„еҪұе“Қ
еҒҮи®ҫдёҖдёӘHDFSз®ЎзҗҶ3дәҝзҡ„е°Ҹж–Ү件пјҢйҖҡиҝҮдј°з®—NameNodeеҚ з”Ёзҡ„еҶ…еӯҳеӨ§жҰӮжҳҜ300GBгҖӮйӮЈд№ҲеҪ“е®ғйҮҚеҗҜж—¶пјҢеҲҷйңҖиҰҒд»Һжң¬ең°зЈҒзӣҳиҜ»еҸ–жҜҸдёӘж–Ү件зҡ„е…ғж•°жҚ®гҖӮиҝҷж„Ҹе‘ізқҖNameNodeйңҖиҰҒеҠ иҪҪ300GBеӨ§е°Ҹзҡ„ж•°жҚ®еҲ°еҶ…еӯҳдёӯпјҢд»ҺиҖҢдёҚеҸҜйҒҝе…Қзҡ„еҜјиҮҙжңҚеҠЎеҗҜеҠЁж—¶й—ҙиҫғй•ҝгҖӮ
еҸҲеӣ дёәNameNodeжҳҜеҹәдәҺJVMиҝҗиЎҢпјҢеҰӮжһңеҚ з”Ё300GBзҡ„еҶ…еӯҳпјҢеҲҷиЎЁзӨәJVMйңҖиҰҒй…ҚзҪ®300GBзҡ„heapпјҢеҪ“JVMжү§иЎҢfull gcж—¶пјҢе°ҶдјҡеҜјиҮҙдёҡеҠЎйҳ»еЎһгҖӮ
еңЁHDFSдёӯпјҢDataNodeдјҡйҖҡиҝҮе®ҡж—¶зҡ„еҝғи·іжқҘдёҠжҠҘе…¶ж•°жҚ®еқ—зҡ„дҪҚзҪ®дҝЎжҒҜпјҢNameNodeдјҡдёҚж–ӯи·ҹиёӘ并жЈҖжҹҘжҜҸдёӘж•°жҚ®еқ—зҡ„еӯҳеӮЁдҪҚзҪ®гҖӮжүҖд»Ҙж•°жҚ®иҠӮзӮ№йңҖиҰҒдёҠжҠҘзҡ„ж•°жҚ®еқ—и¶ҠеӨҡпјҢеҲҷдјҡж¶ҲиҖ—и¶ҠеӨҡзҡ„зҪ‘з»ңеёҰе®ҪпјҢиҝӣиҖҢеҜ№зҪ‘з»ңйҖ жҲҗеҺӢеҠӣгҖӮ
еҶ…еӯҳиҝҮеӨ§еҜјиҮҙе®һйҷ…йҷҗеҲ¶дәҶHDFSдёӯеҸҜд»ҘеӯҳеӮЁзҡ„еҜ№иұЎж•°йҮҸпјҢд№ҹе°ұж„Ҹе‘ізқҖеҜ№дәҺдёҖдёӘжӢҘжңүеӨ§йҮҸж–Ү件зҡ„и¶…еӨ§йӣҶзҫӨжқҘиҜҙпјҢеҶ…еӯҳе°ҶжҲҗдёәйҷҗеҲ¶зі»з»ҹжЁӘеҗ‘жү©еұ•зҡ„瓶йўҲгҖӮ
еҗҢж—¶пјҢдҪңдёәдёҖдёӘеҸҜжү©еұ•зҡ„ж–Ү件系з»ҹпјҢеҚ•дёӘйӣҶзҫӨдёӯж”ҜжҢҒж•°еҚғдёӘиҠӮзӮ№гҖӮеңЁеҚ•дёӘе‘ҪеҗҚз©әй—ҙдёӯDataNodeеҸҜд»Ҙжү©еұ•зҡ„еҫҲеҘҪпјҢдҪҶжҳҜNameNode并дёҚиғҪеңЁеҚ•дёӘе‘ҪеҗҚз©әй—ҙиҝӣиЎҢжЁӘеҗ‘жү©еұ•гҖӮйҖҡеёёжғ…еҶөдёӢпјҢHDFSйӣҶзҫӨзҡ„жҖ§иғҪ瓶йўҲеңЁеҚ•дёӘNameNodeдёҠгҖӮ
05
常规解еҶіж–№жЎҲеҸҠеӯҳеңЁзҡ„й—®йўҳ
иҰҒи§ЈеҶіHadoopдёӯе°Ҹж–Ү件зҡ„й—®йўҳпјҢйҰ–е…ҲиҰҒе°ҪйҮҸеңЁжәҗеӨҙи§ЈеҶій—®йўҳпјҢд№ҹе°ұжҳҜеҜ№дәҺеӣ дёәжҹҗдәӣ组件й…ҚзҪ®дёҚеҗҲзҗҶеҜјиҮҙдә§з”ҹеӨ§йҮҸе°Ҹж–Ү件зҡ„жғ…еҶөпјҢйңҖиҰҒдјҳеҢ–й…ҚзҪ®жқҘеҮҸе°‘е°Ҹж–Ү件зҡ„з”ҹжҲҗгҖӮдҪҶжңүдәӣеңәжҷҜдјҡдёҚеҸҜйҒҝе…Қең°з”ҹжҲҗдёҖдәӣе°Ҹж–Ү件пјҢе°ұйңҖиҰҒеј•е…Ҙе…¶д»–ж–№жЎҲжқҘи§ЈеҶій—®йўҳгҖӮ
HadoopжҸҗдҫӣдәҶеҮ з§Қеёёз”Ёзҡ„ж–№жі•жқҘи§ЈеҶіиҝҷдёӘй—®йўҳпјҢиҝҷдәӣж–№жі•еңЁжҹҗдәӣж–№йқўи§ЈеҶідәҶдёҖе®ҡзҡ„й—®йўҳпјҢдҪҶд№ҹйғҪеӯҳеңЁзқҖеҗ„иҮӘзҡ„дёҚи¶ігҖӮ
1гҖҒиҒ”йӮҰHDFS
еңЁHadoop 2.xеҸ‘иЎҢзүҲдёӯеј•е…ҘдәҶиҒ”йӮҰHDFSеҠҹиғҪпјҢжңҹжңӣеҸҜд»Ҙи§ЈеҶіNameNodeзҡ„еҶ…еӯҳй—®йўҳгҖӮиҒ”йӮҰHDFSе…Ғи®ёзі»з»ҹйҖҡиҝҮж·»еҠ еӨҡдёӘNameNodeжқҘе®һзҺ°жү©еұ•пјҢе…¶дёӯжҜҸдёӘNameNodeз®ЎзҗҶж–Ү件系з»ҹе‘ҪеҗҚз©әй—ҙдёӯзҡ„дёҖйғЁеҲҶгҖӮдҪҶжҳҜпјҢзі»з»ҹз®ЎзҗҶе‘ҳйңҖиҰҒз»ҙжҠӨеӨҡдёӘNameNodeе’ҢиҙҹиҪҪеқҮиЎЎжңҚеҠЎпјҢиҝҷеҸҲеўһеҠ дәҶз®ЎзҗҶжҲҗжң¬гҖӮжүҖд»ҘHDFSзҡ„иҒ”йӮҰж–№жЎҲ并没жңүиў«з”ҹдә§зҺҜеўғжүҖйҮҮз”ЁгҖӮ
2гҖҒеҪ’жЎЈж–Ү件
HadoopеҪ’жЎЈж–Ү件жҲ–HARж–Ү件жҳҜе°ҶHDFSж–Ү件жү“еҢ…еҲ°еҪ’жЎЈдёӯзҡ„е·Ҙе…·гҖӮиҝҷжҳҜеңЁHDFSдёӯеӯҳеӮЁеӨ§йҮҸе°Ҹж–Ү件зҡ„жҜ”иҫғеёёз”Ёзҡ„йҖүжӢ©гҖӮHARж–Ү件зҡ„еҺҹзҗҶжҳҜе°ҶеҫҲеӨҡе°Ҹж–Ү件жү“еҢ…еҲ°дёҖиө·пјҢеҪўжҲҗдёҖдёӘHDFSж–Ү件пјҲжңүзӮ№зұ»дјјLinuxзҡ„TARж–Ү件пјүпјҢиҝҷж ·еҸҜд»Ҙжңүж•Ҳзҡ„еҮҸе°‘HDFSз®ЎзҗҶзҡ„blockж•°йҮҸпјҢд»ҺиҖҢйҷҚдҪҺNameNodeдҪҝз”ЁгҖӮ
еҪ“и®ҝй—®HARж–Ү件зҡ„ж—¶еҖҷпјҢйңҖиҰҒдҪҝз”ЁвҖңhar://вҖқеүҚзјҖгҖӮиҜ»еҸ–HARеҪ’жЎЈж–Ү件зҡ„дёӯзҡ„жҹҗдёӘеӯҗж–Ү件时пјҢйңҖиҰҒе…ҲиҜ»еҸ–HARдёӯзҡ„еӯҗж–Ү件жҳ е°„е…ізі»пјҲзҙўеј•дҝЎжҒҜпјүпјҢд№ҹе°ұжҳҜеӯҗж–Ү件зҡ„дҪҚзҪ®пјҢеҶҚж №жҚ®дҪҚзҪ®дҝЎжҒҜиҺ·еҸ–е®һйҷ…зҡ„ж–Ү件еҶ…е®№гҖӮиҝҷж ·зҡ„е®һзҺ°ж–№ејҸдјҡйҖ жҲҗдёҖе®ҡзҡ„иҜ»жҖ§иғҪжҚҹеӨұгҖӮ
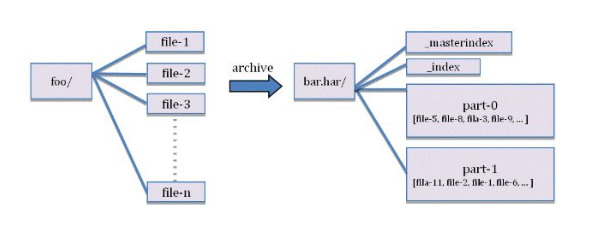
еңЁдҪҝз”ЁHARж—¶пјҢиҰҒжё…жҘҡе“Әдәӣж–Ү件йңҖиҰҒеҒҡеҪ’жЎЈеӨ„зҗҶпјҢиҝҷе°ұеўһеҠ дәҶж–Ү件系з»ҹз®ЎзҗҶзҡ„еӨҚжқӮеәҰгҖӮ
3гҖҒйҖҡиҝҮHBase
з”ЁHBaseжқҘеӯҳеӮЁе°Ҹж–Ү件пјҢд№ҹжҳҜжҜ”иҫғеёёз”Ёзҡ„ж–№жі•д№ӢдёҖгҖӮHBaseеңЁи®ҫи®ЎдёҠдё»иҰҒдёәдәҶеә”еҜ№еҝ«йҖҹжҸ’е…ҘгҖҒеӯҳеӮЁжө·йҮҸж•°жҚ®гҖҒеҚ•дёӘи®°еҪ•зҡ„еҝ«йҖҹжҹҘжүҫд»ҘеҸҠжөҒејҸж•°жҚ®еӨ„зҗҶгҖӮ

еӣҫзүҮжқҘжәҗпјҡClouderaж–ҮжЎЈ
дҪҝз”ЁHBaseпјҢеҸҜд»ҘиҫғеҘҪзҡ„еә”еҜ№е®һж—¶ж•°жҚ®еҶҷе…Ҙд»ҘеҸҠе®һж—¶жҹҘиҜўзҡ„еңәжҷҜпјҢеңЁHBase йҮҢеҗҢдёҖзұ»зҡ„ж–Ү件е®һйҷ…жҳҜеӯҳеңЁеҗҢдёҖдёӘеҲ—ж—ҸдёӢйқўпјҢеҰӮжһңж–Ү件数йҮҸеӨӘеӨҡпјҢдјҡеҜјиҮҙregionserver еҶ…еӯҳеҚ з”ЁиҝҮеӨ§пјҢJVMеҶ…еӯҳиҝҮеӨ§ж—¶gcдјҡеҚЎдёҡеҠЎгҖӮж №жҚ®е®һйҷ…жөӢиҜ•ж— жі•жңүж•Ҳж”ҜжҢҒ10дәҝд»ҘдёҠзҡ„е°Ҹж–Ү件еӯҳеӮЁгҖӮ
06
XSKYи§ЈеҶіж–№жЎҲ
жөҒејҸж•°жҚ®еҜје…ҘиҝҮзЁӢдёӯдә§з”ҹзҡ„е°Ҹж–Ү件жҳҜдёҖдёӘжҜ”иҫғи®©дәәеӨҙз–јзҡ„й—®йўҳгҖӮж №жҚ®еҪ“еүҚйқўдёҙзҡ„жҢ‘жҲҳпјҢXSKYеҜ№иұЎеӯҳеӮЁдә§е“ҒXEOSе’ҢHadoopеӨ§ж•°жҚ®е№іеҸ°з»“еҗҲзҡ„е®һи·өж–№жЎҲпјҢдә’иЎҘдёӨдёӘзі»з»ҹзҡ„дјҳеҠҝгҖӮ
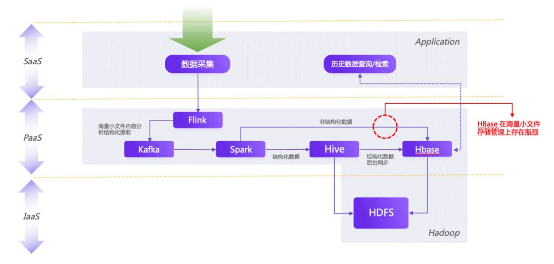
1гҖҒHadoopеҺҹжңүж–№жЎҲпјҡ
2гҖҒXEOS + Hadoopж–°ж–№жЎҲпјҡ
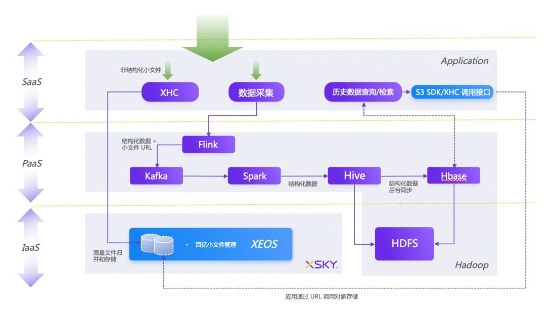
XEOSжҳҜXSKYдё“дёәжө·йҮҸйқһз»“жһ„еҢ–ж•°жҚ®гҖҒй«ҳж•Ҳи·Ёең°еҹҹжҢүйңҖи®ҝй—®е’Ңдә‘еҺҹз”ҹзҡ„еӯҳеӮЁдә§е“ҒгҖӮйҖҡиҝҮе…Ёж–°зҡ„еӯҳеӮЁжҠҖжңҜжүӢж®өпјҢеҹәдәҺйҖҡз”ЁжңҚеҠЎеҷЁзЎ¬д»¶жһ„е»әдәҶдёҖдёӘиҝ‘д№Һж— йҷҗжү©е®№гҖҒжҢҒз»ӯеңЁзәҝгҖҒеҸҜи·Ёең°еҹҹи®ҝй—®зҡ„й«ҳжҖ§д»·жҜ”еӯҳеӮЁжһ¶жһ„дҪ“зі»пјҢеңЁдҝқиҜҒдәҶж•°жҚ®й«ҳе®үе…ЁжҖ§зҡ„еҗҢж—¶пјҢжү“з ҙеӯҳеӮЁи§„жЁЎе’Ңең°еҹҹйҷҗеҲ¶зҡ„еЈҒеһ’пјҢйҷҚдҪҺдјҒдёҡITе»әи®ҫзҡ„жҠ•е…ҘпјҢж»Ўи¶ідәҶж–°дёҡеҠЎеҪўжҖҒзҡ„еӨҡжәҗеҢ–еӯҳеӮЁйңҖжұӮгҖӮ
йҖҡиҝҮXEOSжқҘеӯҳеӮЁз®ЎзҗҶжүҖжңүжө·йҮҸж–Ү件数жҚ®пјҢеә”з”Ёе°Ҷе°Ҹж–Ү件з»ҹдёҖеӯҳеӮЁеҲ°XEOSеӯҳеӮЁзі»з»ҹпјҢеҗҢж—¶е°ҶйҮҮйӣҶеҲ°зҡ„з»“жһ„еҢ–ж•°жҚ®еӯҳеӮЁеңЁXEOSдёӯпјҢе°Ҹж–Ү件зҡ„URLйҖҡиҝҮFlinkе’ҢKafkaжңҚеҠЎиҝӣиЎҢжөҒиҪ¬пјҢжңҖз»Ҳе°Ҷе°Ҹж–Ү件URLе’Ңз»“жһ„еҢ–ж•°жҚ®еӯҳеӮЁеҲ°HiveдёӯпјҢжңҖз»ҲеҗҺеҸ°дјҡе°Ҷж•°жҚ®еҗҢжӯҘеҲ°HBaseгҖӮ
дёҡеҠЎеңЁеҜ№ж•°жҚ®иҝӣиЎҢжҹҘиҜўжЈҖзҙўж—¶пјҢеҸҜд»Ҙд»ҺHBaseдёӯиҺ·еҸ–еҺҹе§Ӣж–Ү件数жҚ®еңЁXEOSеӯҳеӮЁдёӯзҡ„URLдҝЎжҒҜпјҢйҖҡиҝҮURLзӣҙжҺҘд»ҺXEOSеӯҳеӮЁдёӯиҜ»еҸ–еҜ№еә”зҡ„ж–Ү件数жҚ®пјҢиҜҘж–№жЎҲе®ҢзҫҺи§ЈеҶідәҶеҺҹжқҘHadoopж–№жЎҲзҡ„жө·йҮҸе°Ҹж–Ү件еӯҳеӮЁз“¶йўҲй—®йўҳгҖӮ
07
еӯҳеӮЁзү№жҖ§д»Ӣз»Қ
1гҖҒжө·йҮҸе°Ҹж–Ү件管зҗҶ
жө·йҮҸе°Ҹж–Ү件еӨ„зҗҶзҡ„瓶йўҲеңЁдәҺеҜ№е…ғж•°жҚ®зҡ„еӨ„зҗҶпјҢXEOSеҜ№иұЎеӯҳеӮЁдә§е“ҒеҜ№е…ғж•°жҚ®зҡ„еӯҳеӮЁе’Ңз®ЎзҗҶйҮҮз”ЁдәҶRocksDBпјҢRocksDBе…·жңүеҫҲеҘҪзҡ„еҶҷжҖ§иғҪгҖӮ
жҜҸдёӘзЈҒзӣҳе…ғж•°жҚ®еҲҶеҢәйғЁзҪІ1дёӘRocksDBе®һдҫӢпјҢ规еҲ’дёҖз»„зЈҒзӣҳз»„жҲҗдёҖдёӘRocksDBйӣҶзҫӨпјҲзҙўеј•жұ пјүгҖӮзәҜSSDзӣҳжҲ–ж··еҗҲзӣҳйҮҮз”ЁеүҜжң¬ж–№ејҸпјҢз”ЁдәҺеӯҳеӮЁжүҖжңүе…ғж•°жҚ®пјҢж»Ўи¶ізҷҫдәҝе…ғж•°жҚ®з®ЎзҗҶзҡ„еҗҢж—¶иҝӣдёҖжӯҘжҸҗй«ҳдәҶе…ғж•°жҚ®и®ҝй—®ж•ҲзҺҮгҖӮ
е…ғж•°жҚ®з®ЎзҗҶ-зҙўеј•жұ жһ¶жһ„пјҲд»Ҙж··еҗҲзӣҳдёәдҫӢпјүпјҡ
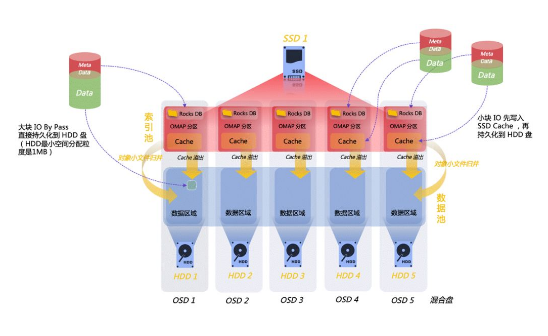
еҜ№иұЎзҙўеј•жұ дёҚдҪҶжүҝиҪҪе…ғж•°жҚ®з®ЎзҗҶеҠҹиғҪпјҢиҝҳжүҝиҪҪдәҶеҲҶеёғејҸзј“еӯҳеҠҹиғҪпјҢе°Ҹж–Ү件еҶҷе…ҘSSDзј“еӯҳеҲҶеҢәеҗҺеҚіиҝ”еӣһжҲҗеҠҹпјҢиҝӣдёҖжӯҘжҸҗеҚҮеҲҶеёғејҸеӯҳеӮЁеҜ№жө·йҮҸе°Ҹж–Ү件зҡ„жҖ§иғҪж”ҜжҢҒгҖӮ
еңЁиө„жәҗз®ЎзҗҶж–№йқўпјҢеҸҜеҗҢж—¶ж”ҜжҢҒеүҜжң¬еҸҠECе®үе…Ёзӯ–з•ҘпјҢHDDзӣҳйҮҮз”ЁECзӯ–з•ҘпјҢз”ЁдәҺеӯҳеӮЁжңҖз»Ҳж–Ү件数жҚ®гҖӮйҮҮз”ЁеүҜжң¬е’ҢECй…ҚеҗҲзҡ„е®үе…Ёзӯ–з•ҘпјҢеңЁж»Ўи¶іжө·йҮҸе°Ҹж–Ү件еӯҳеӮЁеҸҠй«ҳжҖ§иғҪзҡ„еҗҢж—¶еӨ§е№…жҸҗеҚҮеӯҳеӮЁз©әй—ҙеҲ©з”ЁзҺҮгҖӮ
2гҖҒе°Ҹж–Ү件еҪ’并
XEOSеҜ№иұЎеӯҳеӮЁзі»з»ҹеҸҜиҮӘиҜҶеҲ«ж–Ү件еӨ§е°ҸпјҢе®һзҺ°е°Ҹж–Ү件еҪ’并еӯҳеӮЁпјҢеӨ§ж–Ү件еҲҮзүҮеӯҳеӮЁжҠҖжңҜпјҢйҷҚдҪҺжө·йҮҸе°Ҹж–Ү件еҶҷе…Ҙзҡ„йҡҸжңәжҖ§пјҢжҸҗеҚҮеӨ§ж–Ү件иҜ»еҶҷж•ҲзҺҮгҖӮ
еҜ№иұЎзҙўеј•жұ еӯҳж”ҫж–Ү件е…ғж•°жҚ®е’Ңе°ҸдәҺ1MBзҡ„е°Ҹж–Ү件数жҚ®пјҢеҠ йҖҹжө·йҮҸж–Ү件йҒҚеҺҶж•ҲзҺҮгҖӮеҪ“е°Ҹж–Ү件数йҮҸиҫҫеҲ°дёҖе®ҡж•°йҮҸж—¶пјҢзі»з»ҹиҮӘеҠЁиҜҶеҲ«е°ҸдәҺ4MBзҡ„е°Ҹж–Ү件数жҚ®йғҪдјҡеҪ’并дёә32MBзҡ„иҝһз»ӯеӨ§ж–Ү件пјҢеӯҳеӮЁеҲ°ECж•°жҚ®жұ пјҢдёҚд»…еӨ§еӨ§жҸҗй«ҳдәҶеҶҷжҖ§иғҪпјҢд№ҹеўһеҠ дәҶеӯҳеӮЁз©әй—ҙзҡ„еҲ©з”ЁзҺҮгҖӮ
3гҖҒеӨҡжҙ»еҠЁжұ -ж•ҙжұ жү©е®№
дёәдәҶж»Ўи¶іжө·йҮҸж•°жҚ®зҡ„иҝ…йҖҹеўһй•ҝпјҢXEOSж”ҜжҢҒеӨҡжҙ»еҠЁжұ еҸҠж•ҙжұ жү©е®№еҠҹиғҪпјҢеңЁеӯҳеӮЁзӯ–з•Ҙдёӯж·»еҠ еӨҡдёӘеӯҳеӮЁжұ пјҢеӯҳеӮЁж•°жҚ®ж—¶дјҡж №жҚ®ж•°жҚ®жұ зҡ„еү©дҪҷеҸҜз”Ёз©әй—ҙжқғйҮҚиҪ®иҜўйҖүжӢ©д»ҺдёҚеҗҢзҡ„ж•°жҚ®жұ еҲҶй…ҚеӯҳеӮЁз©әй—ҙдҪҝз”ЁпјҢиҝҷдәӣеҸҜдҫӣеҶҷе…Ҙж–°ж•°жҚ®зҡ„иө„жәҗжұ з§°дёәжҙ»еҠЁжұ гҖӮ
ж №жҚ®йңҖиҰҒеҸҜд»Ҙе°Ҷжҙ»еҠЁжұ и®ҫзҪ®жҲҗдёәйқһжҙ»еҠЁжұ пјҢж–°еҶҷе…Ҙж•°жҚ®ж—¶дёҚеҶҚд»Һйқһжҙ»еҠЁжұ еҲҶй…Қз©әй—ҙгҖӮдҪҶж— и®әжҳҜжҙ»еҠЁжұ иҝҳжҳҜйқһжҙ»еҠЁжұ пјҢеҜ№е·Із»ҸеӯҳеӮЁеңЁиө„жәҗжұ дёӯзҡ„ж•°жҚ®пјҢйғҪеҸҜд»ҘиҜ»еҸ–жҲ–еҲ йҷӨгҖӮ
еҰӮжһңзҺ°жңүеӯҳеӮЁжұ з©әй—ҙе·ІдёҚж»Ўи¶іеӯҳеӮЁеўһйҮҸйңҖжұӮпјҢеҸҜд»Ҙе°Ҷж–°иө„жәҗжұ еҠ е…ҘеӯҳеӮЁзӯ–з•Ҙжҙ»еҠЁжұ з»„дёӯпјҢеҚіеҸҜжҠ•е…ҘдҪҝз”ЁгҖӮиҝҷз§Қжү©е®№ж–№ејҸпјҢдёҚдјҡдә§з”ҹд»»дҪ•ж•°жҚ®йҮҚе№іиЎЎпјҢеҸҜжңүж•ҲйҒҝе…Қж•°жҚ®йҮҚе№іиЎЎеҜ№еүҚз«ҜдёҡеҠЎзҡ„еҶІеҮ»гҖӮж №жҚ®еҗ„дёӘжҙ»еҠЁжұ зҡ„еҸҜз”Ёз©әй—ҙжқғйҮҚиҪ®иҜўеҲҶй…ҚеӯҳеӮЁз©әй—ҙеҶҷе…Ҙж•°жҚ®пјҢж–°гҖҒж—§иө„жәҗжұ еҗҢж—¶дҪҝз”ЁпјҢиҒҡеҗҲжҖ§иғҪе’Ңе®№йҮҸеҗҢж—¶жҸҗеҚҮгҖӮ
4гҖҒз”ҹе‘Ҫе‘Ёжңҹз®ЎзҗҶпјҢиҝҮжңҹеҲ йҷӨ
XEOSдёәз”ЁжҲ·жҸҗдҫӣдәҶдё°еҜҢзҡ„ж•°жҚ®еӯҳеӮЁе’Ңз®ЎзҗҶжңәеҲ¶гҖӮж”ҜжҢҒд»ҘеӯҳеӮЁжЎ¶зІ’еәҰзҡ„ж•°жҚ®з”ҹе‘Ҫе‘Ёжңҹз®ЎзҗҶпјҢеҸҜд»ҘеҜ№еӯҳеӮЁжЎ¶еҶ…зҡ„ж•°жҚ®йҖҡиҝҮеҢ№й…ҚиҝҮжңҹжқЎд»¶е’Ң规еҲҷиҝӣиЎҢеҲ йҷӨпјҢеҗҢж—¶ж”ҜжҢҒ延时еҲ йҷӨгҖӮ
ж №жҚ®дёҡеҠЎеҜ№ж•°жҚ®зҡ„еӯҳеӮЁйңҖжұӮпјҢй…ҚзҪ®жүҖжңүзӣёе…іжЎ¶зҡ„з”ҹе‘Ҫе‘Ёжңҹ规еҲҷпјҢи®ҫзҪ®иҝҮжңҹеҲ йҷӨж—¶й—ҙпјҢеӯҳеӮЁжЎ¶дёӯзҡ„ж•°жҚ®дјҡж №жҚ®ж•°жҚ®зҡ„еҶҷе…Ҙж—¶й—ҙејҖе§Ӣи®Ўз®—пјҢиҫҫеҲ°еҲ йҷӨжқЎд»¶ж•°жҚ®зҡ„еҚіжү§иЎҢеҲ йҷӨж“ҚдҪңпјҢйҮҠж”ҫз©әй—ҙпјҢжҸҗй«ҳеӯҳеӮЁз©әй—ҙзҡ„еҲ©з”ЁзҺҮгҖӮ
08
жҖ»з»“
XSKYеҜ№иұЎеӯҳеӮЁдә§е“ҒXEOSе’ҢHadoopеӨ§ж•°жҚ®е№іеҸ°з»“еҗҲзҡ„е®һи·өж–№жЎҲпјҢиЎҘе……дәҶHadoopеңЁз®ЎзҗҶе®һж—¶е°Ҹж–Ү件дёҠзҡ„дёҚи¶іпјҢеҫҲеҘҪзҡ„и§ЈеҶідәҶHadoopз®ЎзҗҶжө·йҮҸе°Ҹж–Ү件зҡ„й—®йўҳпјҢXEOSж”ҜжҢҒзҡ„жө·йҮҸе°Ҹж–Ү件管зҗҶеҸҠж–Ү件еҪ’并зү№жҖ§еҫҲеҘҪзҡ„йқўеҜ№жө·йҮҸж•°жҚ®еўһй•ҝйңҖжұӮгҖӮ
еӨҡжҙ»еҠЁжұ еҸҠж•ҙжұ жү©е®№еҠҹиғҪеҸҜж”ҜжҢҒзҒөжҙ»жү©е®№пјҢдёҚдҪҶдёҚеҪұе“ҚдёҡеҠЎжӯЈеёёдҪҝз”ЁпјҢиҝҳеҸҜд»Ҙж–°гҖҒж—§иө„жәҗжұ еҗҢж—¶дҪҝз”ЁпјҢиҒҡеҗҲжҖ§иғҪе’Ңе®№йҮҸеҗҢж—¶жҸҗеҚҮгҖӮзҒөжҙ»зҡ„з”ҹе‘Ҫе‘Ёжңҹз®ЎзҗҶеӨ§еӨ§йҷҚдҪҺдәҶж•°жҚ®еӯҳеӮЁжҲҗжң¬пјҢжҸҗй«ҳдәҶз©әй—ҙеҲ©з”ЁзҺҮгҖӮз»“еҗҲHadoopеӨ§ж•°жҚ®е№іеҸ°жҲҗзҶҹзҡ„еҲҶжһҗеҸҠе…ғж•°жҚ®з®ЎзҗҶжҠҖжңҜпјҢдёәдёҡеҠЎи®ҝй—®жҸҗдҫӣдәҶжӣҙеҘҪжҖ§иғҪгҖӮ
йҡҸзқҖе®ўжҲ·дёҡеҠЎдёҚж–ӯеўһй•ҝе’ҢеҜ№ж•°жҚ®жңүдёҚеҗҢи®ҝй—®е’Ңз®ЎзҗҶйңҖжұӮпјҢXSKYеҜ№иұЎеӯҳеӮЁдә§е“ҒиҝҳеҸҜд»Ҙж”ҜжҢҒж №жҚ®дёҚеҗҢи®ҝй—®йңҖжұӮзҡ„ж•°жҚ®иҝӣиЎҢж•°жҚ®еҲҶеұӮпјҢе°ҶеҜ№и®ҝй—®йў‘зҺҮдёҚй«ҳзҡ„ж•°жҚ®еӯҳеӮЁеҲ°жҖ§иғҪдҪҺеӯҳеӮЁд»ӢиҙЁдёӯиҝӣиЎҢз®ЎзҗҶпјҢеҗҢж—¶ж”ҜжҢҒеҲҶеұӮеҲ°дә‘з«Ҝз®ЎзҗҶгҖӮ
IT и§ЈеҶіж–№жЎҲпјҡ
XSKYжңҚеҠЎеҷЁиҷҡжӢҹеҢ–и§ЈеҶіж–№жЎҲ
XSKYз§Ғжңүдә‘и§ЈеҶіж–№жЎҲ
XSKYе®№еҷЁи§ЈеҶіж–№жЎҲ
XSKYдјҒдёҡзә§еә”з”Ёи§ЈеҶіж–№жЎҲ
XSKYжЎҢйқўиҷҡжӢҹеҢ–пјҲVDIпјүи§ЈеҶіж–№жЎҲ
XSKYе®№зҒҫи§ЈеҶіж–№жЎҲ
XSKYејҖеҸ‘жөӢиҜ•е№іеҸ°и§ЈеҶіж–№жЎҲ
XSKYеҲҶж”Ҝжңәжһ„и§ЈеҶіж–№жЎҲ
XSKYж–°е»әж•°жҚ®дёӯеҝғи§ЈеҶіж–№жЎҲ
еә”з”ЁеңәжҷҜпјҡ
еҸҢжҙ»
е®№еҷЁ
еӨ§ж•°жҚ®
дә‘е№іеҸ°
дә‘жЎҢйқў
дә§е“Ғи§„ж јпјҡ
SDS иҪҜ件
XCBS дә‘еҗҺз«ҜеӯҳеӮЁ
XEBS еқ—еӯҳеӮЁ
XEUS з»ҹдёҖеӯҳеӮЁ
XEOS еҜ№иұЎеӯҳеӮЁ
XEDP з»ҹдёҖж•°жҚ®е№іеҸ°
SDS дёҖдҪ“еҢ–дә§е“Ғ
XSCALER EXPRESS 2000пјҡXE2020гҖҒXE2030гҖҒXE2050
XSCALER 3000
жңҚеҠЎеҢәеҹҹпјҡ
жҲҗйғҪ xskyгҖҒз»өйҳі xskyгҖҒиҮӘиҙЎ xskyгҖҒж”ҖжһқиҠұ xskyгҖҒжіёе·һ xskyгҖҒ
еҫ·йҳі xskyгҖҒе№ҝе…ғ xskyгҖҒйҒӮе®Ғ xskyгҖҒеҶ…жұҹ xskyгҖҒд№җеұұ xskyгҖҒ
иө„йҳі xskyгҖҒе®ңе®ҫ xskyгҖҒеҚ—е…… xskyгҖҒиҫҫе·һ xskyгҖҒйӣ…е®ү xskyгҖҒ
йҳҝеққи—Ҹж—ҸзҫҢж—ҸиҮӘжІ»е·һ xskyгҖҒеҮүеұұеҪқж—ҸиҮӘжІ»е·һ xskyгҖҒе№ҝе®ү xskyгҖҒе·ҙдёӯ xskyгҖҒзңүеұұ xsky
жңҚеҠЎеҶ…е®№пјҡ
иҪҜ件е®үиЈ…йғЁзҪІжңҚеҠЎ
дёҡеҠЎеҜ№жҺҘжңҚеҠЎ
ж•…йҡңеӨ„зҗҶдёҺз”ҹдә§еҸҳжӣҙжңҚеҠЎ
SDS жһ¶жһ„е’ЁиҜўжңҚеҠЎ
ж•°жҚ®иҝҒ移жңҚеҠЎ
зҺ°еңәдҝқйҡңжңҚеҠЎ
йӣҶзҫӨзҺҜеўғеҸҳжӣҙжңҚеҠЎ
еҒҘеә·е·ЎжЈҖжңҚеҠЎ
йӣҶзҫӨзҺҜеўғдјҳеҢ–жңҚеҠЎ
йӣҶзҫӨеҚҮзә§жңҚеҠЎ
жҺҘеҸЈејҖеҸ‘жңҚеҠЎ
йӣҶзҫӨй«ҳзә§е®һж–ҪжңҚеҠЎ
ж–ҮжЎЈејҖеҸ‘жңҚеҠЎ
ејҖжәҗ SDS еҚҮзә§жңҚеҠЎ
жҠҖжңҜжңҚеҠЎз»ҸзҗҶпјҲTAMпјү
з”ҹдә§зә§еҲҶеёғејҸеқ—еӯҳеӮЁпјҢеҲҶеёғејҸеӯҳеӮЁ SDS жЁӘеҗ‘жү©еұ•еӯҳеӮЁпјҢиҪҜ件е®ҡд№үеқ—еӯҳеӮЁзі»з»ҹ
XSKY пјҡSDSпјҢиҪҜ件е®ҡд№үеӯҳеӮЁпјҢеҲҶжӯҘејҸеӯҳеӮЁпјҢеҲҶеёғејҸиҪҜ件е®ҡд№үеӯҳеӮЁ
жҲҗйғҪ科жұҮ科жҠҖжңүйҷҗе…¬еҸё( SDS и§ЈеҶіж–№жЎҲ专家пјү
ең°еқҖпјҡжҲҗйғҪеёӮдәәж°‘еҚ—и·Ҝеӣӣж®ө1еҸ·ж—¶д»Јж•°з ҒеӨ§еҺҰ18F
з”өиҜқпјҡ400-028-1235
QQ: 2231749852
жүӢжңәпјҡ138 8074 7621пјҲеҫ®дҝЎеҗҢеҸ·пјү
